
구문분석
어휘분석
int x12;
x12 = 1 + 5 * 2;
if x12>10 then ...문자 : i, n, t, x, 1, 2, ;, =, +, 5, *, f, >, ...
↓ 어휘 분석(토큰, 즉 최소한의 단어단위로 묶음)
어휘 : int, x12, ;, =, 1, +, 5, if, >, 10, then, ...
↓ 구문 분석(프로그래밍 언어의 구문 규칙을 분석)
구문: <선언문> ::= <자료형> <변수>;
<대입문> ::= <변수> = <수식> ;
어휘분석
프로그램에서 사용된 단어를 구별해 냄
토큰
어휘 분석을 통해 얻어지는 결과(연산자, 구분자, 식별자, 예약어 등)
- 연산자 : +-*/= 등
- 구분자: , ; { } ( ) [ ] 등
- 식별자 : 변수나 함수등의 이름을 나타내는 토큰 (x12, printf 등)
전통적인 식별자 규칙 : 문자와 숫자로 구성, 첫 글자는 문자
<identifier> ::= <letter> | <identifier><letter>
| <identifier><digit>
<letter> ::= A | B | C ... | X | Y | Z
a | b | c ... | x | y | z
<digit> ::= 0 | 1 | 2 | ... | 8 | 9- 예약어 : 프로그래밍 언어 자체에 정의되어 포함된 토큰(if, for, int 등)
식별자와 구문 구조가 같지만 식별자로 사용 못함.
파스트리
유도(derivation)
- 구문 규칙을 이용하여 주어진 프로그램을 만들어내는 과정
- 유도가 가능하면 문법적 오류가 없는 유효한 프로그램이다.
ex) 수식 1+5*2
구문규칙
<exp> ::= <exp>+<ex[> | <exp>-<exp> | <exp>*<exp> | <exp>/<exp> | (<exp>) | <digit>
<digit> ::= 0 | 1 | 2 | ... | 8 | 9유도
<exp>
→ <exp> + <exp>
→ <exp> + <exp> * <exp>
→ <exp> + <exp> * <digit>
→ <exp> + <exp> * 2
→ <exp> + <digit> * 2
→ <exp> + 5 * 2
→ <digit> + 5 * 2
→ 1 + 5 * 2
파스 트리(parse tree)
유도를 트리 형태로 나타낸 것
구조
- 루트 노드 : 시작 비단말 기호
- 비단말 노드 : 비단말 기호, 자식이 있는 노드
- 단말 노드 : 단말 기호, 자식이 없는 노드
단말 노드를 왼쪽부터 오른쪽으로 차례로 나열하면 주어진 프로그램이 됨.

단말노드 : 1 + 5 * 2
파스트리가 존재하지 않으면 오류가 있는 표현임.
ex) 1 + 5 *
1 + 5 * <digit>에서 <digit>은 비단말 노드인데 표현할 수 없으므로 잘못된 표현임을 알 수 있다.
모호성
주어진 표현에 대한 파스 트리가 존재하면 구문에 부합하는 표현딤
만약 주어진 표현에 대한 파스 트리가 여러 개 존재한다면?
- 구문론 관점 : 파스 트리가 존재하므로 구문에는 부합
- 의미론 관점 : 주어진 표현이 서로 다른 의미로 해석될 수 있음
ex) 1 + 5 * 2
왼쪽 파스트리는 1+(5*2) , 오른쪽 트리는 (1+5)*2 로 계산 된다.
모호한 문법
동일한 표현에 대해 서로 다른 파스 트리가 만들어지는 문법
문제점
- 하나의 프로그램이 서로 다른 결과를 도출할 수 있음
- 프로그래머의 의도와는 다르게 해석되어 잘못된 결과를 도출할 수 있는 위험을 내포
문법의 명확화
- 의도하지 않은 의미로 해석되지 않도록 모호한 문법을 명확하게 변경
- 새로운 비단말 기호와 새로운 구문 규칙을 추가하여 변경
ex)
연산자 우선순위
+, - : 가장 낮음
*, / : 중간
(, ) : 가장 높음
모호한 문법
<exp> ::= <exp>+<exp> | <exp>-<exp> | <exp>*<exp> | <exp>/<exp> | (<exp>) | <digit>
<digit> ::= 0 | 1 | 2 | ... | 8 | 9수정
<exp> ::= <exp>+<exp> | <exp>-<exp> | <term>
<term> ::= <term>*<term> | <term>/<term> | <factor>
<factor> ::= (exp) | <digit>
<digit> ::= 0 | 1 | 2 | ... | 8 | 9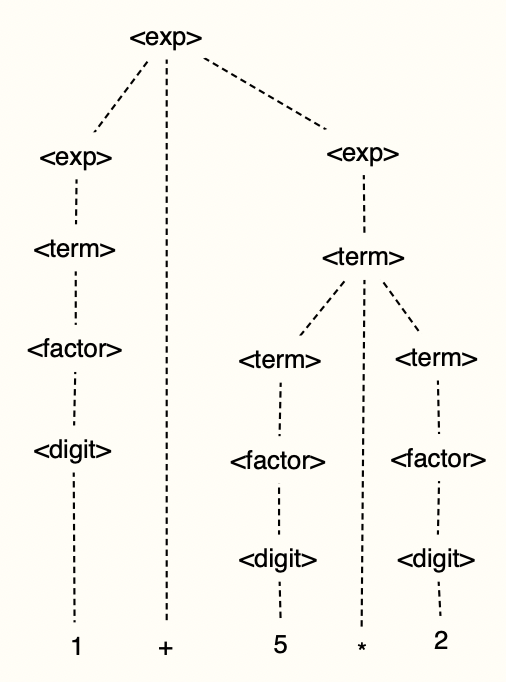
계산은 트리 아래쪽에서부터 하기 때문에 * 먼저 계산된다.
좌결합 연산자
우선순위가 동일한 연산자 사이의 계산 순서는 왼쪽이 우선
ex) 5-3+2
모호한 문법
<exp> ::= <exp>+<exp> | <exp>-<exp> | <term>
<term> ::= <term>*<term> | <term>/<term> | <factor>
<factor> ::= (exp) | <digit>
<digit> ::= 0 | 1 | 2 | ... | 8 | 9수정
<exp> ::= <exp>+<term> | <exp>-<term> | <term>
<term> ::= <term>*<factor> | <term>/<factor> | <factor>
<factor> ::= (exp) | <digit>
<digit> ::= 0 | 1 | 2 | ... | 8 | 9<exp>+<term>이 된 경우 <term>에서 덧셈은 더이상 밑으로 나아갈 수 없기 때문에 왼쪽 우선순위가 지켜진다.
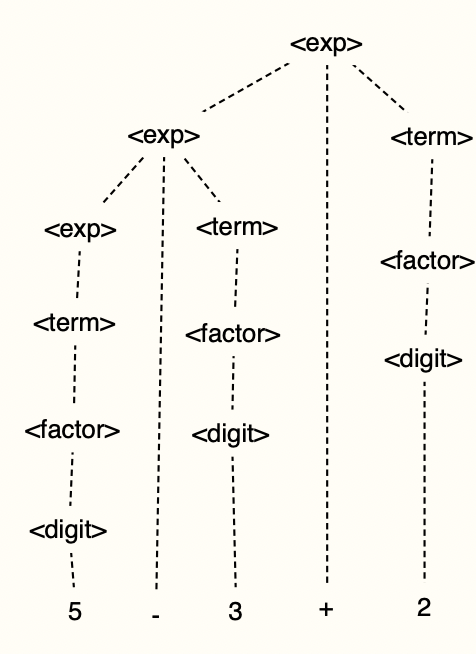
<exp>-<term>을 먼저 표현하면 +를 표현할 수 없기 때문에 좌결함 순서가 지켜진다.
중첩된 if문의 else
중첩된 if문에서 else문의 개수가 if문의 개수보다 적은 경우 각 else문을 어느 조건이 거짓일 때 수행해야 하는지 모호
ex) if x>1 then if x<5 then y=1 else y=2
모호한 문법
<if문> ::= if <논리식> then <문장> else <문장> | if <논리식> then <문장>
<문장> ::= <if문> | <대입문> ...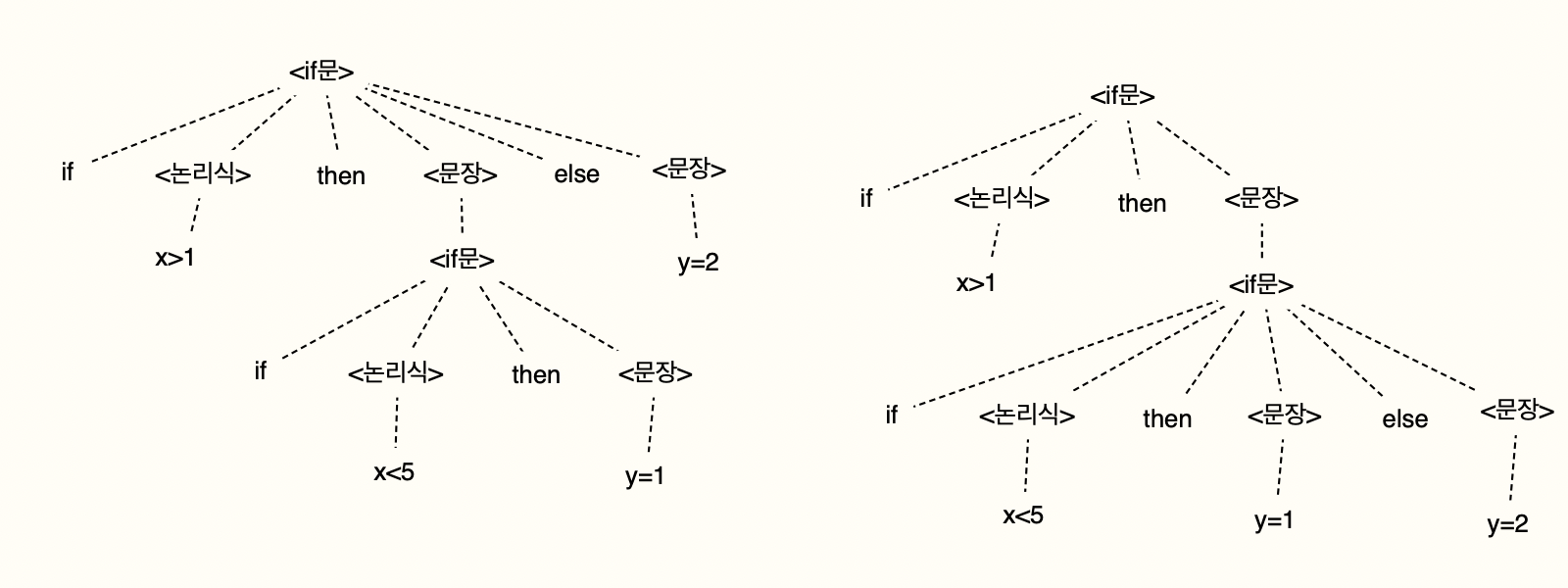
두 가지 해석이 가능하다.
왼쪽 : if x>1 then (if x<5 then y=1) else y=2
오른쪽 : if x>1 then (if x<5 then y=1 else y=2)
수정
* else 문 앞에 나온 if문들 중 다른 else문과 짝이 되지 않은 가장 가까운 if문과 짝이 되도록 함.
<if문> ::= if <논리식> then <문장2> else <문장> | if <논리식> then <문장>
<if문2> ::= if <논리식> then <문장2> else <문장2>
<문장> ::= <if문> | <대입문> ...
<문장2> ::= <if문2> | <대입문> ...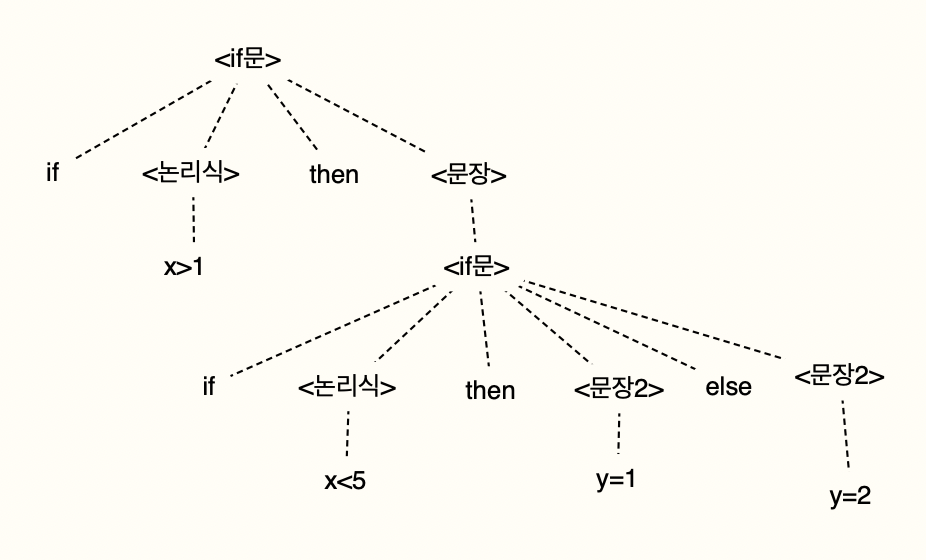
if문2에는 if-then 구문이 없기 때문에 완성시킬 수 없다.